
If King Tut were around today, could he send a text in Egyptian hieroglyphics? Yes, with the right font and keyboard. That’s because the writing system of the pharaohs has already been included in the Unicode Standard, meaning that a character like the Eye of Horus has a code point, 13080, that will render the same way on a tablet in Cairo and a smartphone in Beijing. Because Mayan hieroglyphs have yet to be encoded, the ancient Mayan emperor K’inich Janaab’ Pakal would have to stick to emoji—but that’s about to change.


Unicode is the international encoding standard that makes it possible for users to read, write, and search in a wide range of written languages on all manner of devices without technical miscommunication. Made up of a mix of academics, stakeholders, and interested volunteers, the Unicode Consortium has encoded 139 of the writing systems, technically known as scripts, ever to have existed. Given that alphabets like Cyrillic, Arabic, and Devanagari serve more than 60 languages each and that 500 languages use the Latin alphabet, Unicode makes electronic communication possible in almost a thousand languages. But there are more than a hundred writing systems to go.
In June 2017, the Unicode Consortium rolled out its tenth version in 26 years, which included four scripts as well as the Bitcoin sign and 56 new emoji. The scripts introduced this year include Nüshu, a writing system that was developed by women in the Hunan Province of nineteenth-century China as a workaround when they were denied formal education. Also newly available is Zanabazar Square, created by a Mongolian monk in the seventeenth century to write spiritual texts in Mongolian, Tibetan, and Sanskrit. Crucial as these steps toward cultural empowerment may be, it is the textable faces, socks, mermen, and the like that have brought this global standard into the limelight.
As Michael Erard, writer-in-residence at the Max Planck Institute for Psycholinguistics, recently pointed out in the New York Times, the incorporation of emoji into Unicode is a double-edged sword for those interested in preserving ancient and minority languages. While, on the one hand, emoji eat up the time of the already strapped volunteers who could be working on other scripts, customer demand for emoji also incentivizes voting members of the Unicode Consortium like Microsoft, Apple, and Google’s Alphabet to update their systems with each new version that Unicode releases. Each version includes entirely new writing systems, along with additional letters and symbols for already encoded ones, meaning that, when devices update to get the newest emoji, they also gain access to any other new or revised characters that the Unicode team has developed.
While these companies are in theory supportive of making the scripts of lower-profile languages available, consumer demand for emoji plays a large part in keeping the Unicode Standard updated. “The thing about the emoji is that they are so wildly popular,” says Deborah Anderson, a researcher in the Department of Linguistics at UC Berkeley. “People really want those—well, not the broccoli—but they really want some of these emoji on their phones.”
Anderson leads Berkeley’s Script Encoding Initiative, a project that helps those who want new scripts encoded to draw up compelling proposals and make their writing systems as ready for the transition into the Unicode Standard as possible. The SEI has shepherded nearly 100 scripts into the Unicode Standard, with many more on the horizon. Encoded writing systems include newly minted scripts like Adlam, an alphabet created in the 1980s for the 40 million speakers of Fulani across Africa, as well as ancient writing systems like Coptic, the Egyptian language that has been pivotal for biblical studies. Anderson, who is also a Unicode technical director, joined the cause in 2001, when her work on a publication for Indoeuropean languages at UCLA led her to a roadblock. Trying to write characters in an ancient language from the Italic peninsula, “I found out, ‘Well, you can’t, for an HTML page.’ You couldn’t do it because they weren’t yet in Unicode.” Anderson linked up with the Unicode technical director at the time and the current technical vice president, Ken Whistler and Rick McGowan, respectively, who asked her to be their advocate for historical scripts.

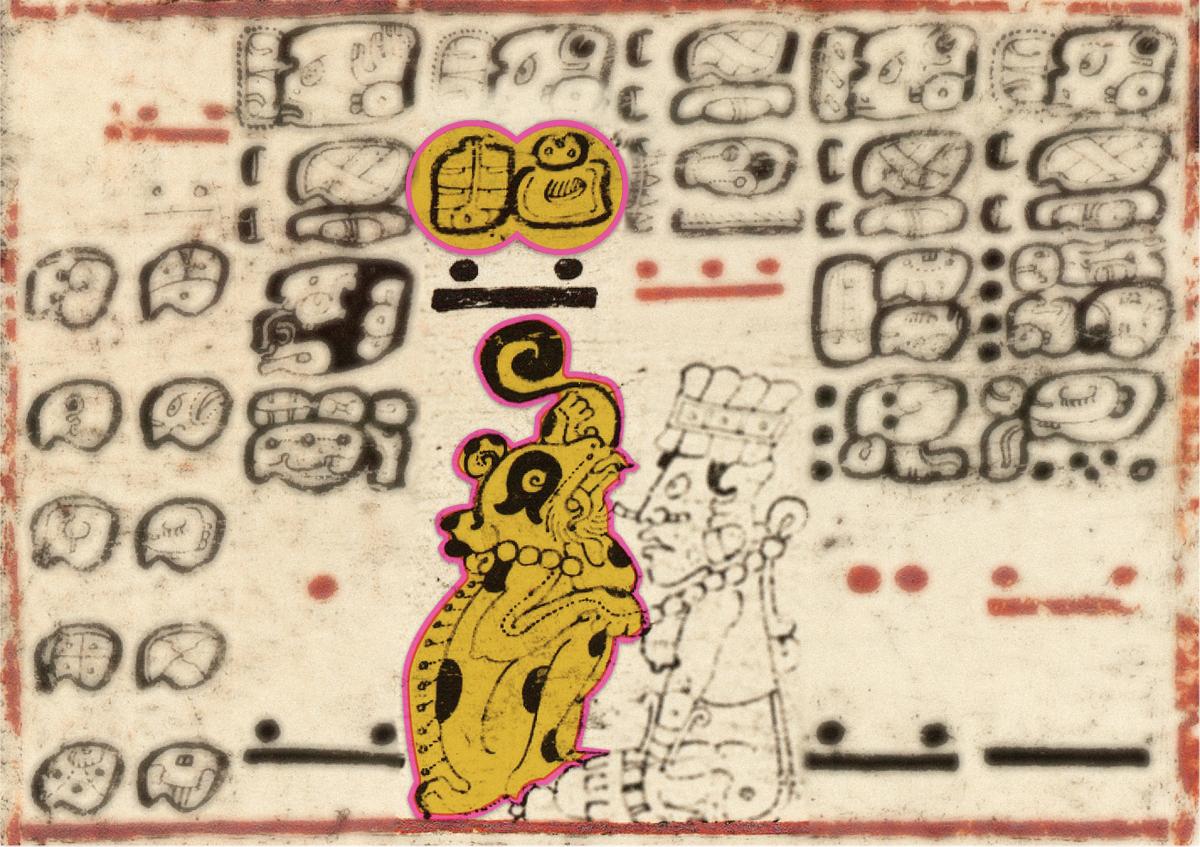
The Dresden Codex is being used to by scholars working to get Mayan hieroglyphs into the unicode standard. Gods and demons are shown in this section of the Codex.
Chronicle / Alamy Stock Photo

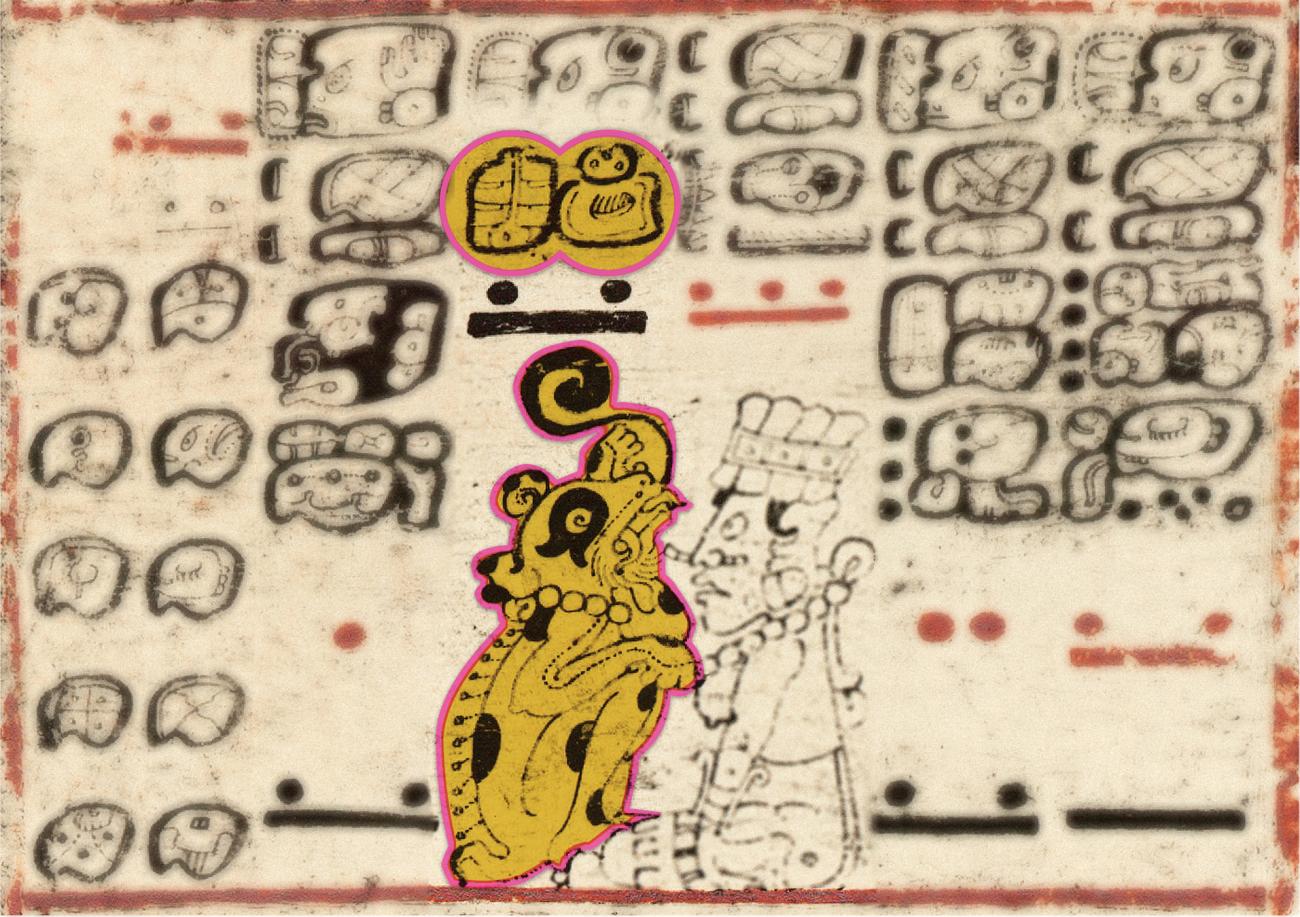
The Dresden Codex is being used to by scholars working to get Mayan hieroglyphs into the unicode standard. Gods and demons are shown in this section of the Codex.
Chronicle / Alamy Stock Photo
Since every detail of a writing system has to be debated and approved before it can even begin to be encoded, getting a script into the Unicode Standard takes a minimum of two years. Any user in the world can propose a change to a pending writing system, and the pace of progress is dictated, in large part, by the time it takes to reach a global consensus on issues like the script’s name and the details of its characters. Disagreements about whether to call a writing system “Old Hungarian” or “Székely-Hungarian Rovás,” for example, caused the encoding process to drag on for 17 years from the date of the first proposal. In the case of Gurmukhi, a writing system that was originally used for Sikh scriptures and is written today by speakers of Punjabi, some argued that the shape and pronunciation of a particular letter’s current form were unfaithful to the original religious texts.
More than 70 writing systems have made it into the Unicode Standard thanks to NEH, which began funding the SEI’s Universal Scripts Project in 2005. “If it wasn’t for NEH support,” says Anderson, “it would really slow the whole process down and a lot of the scripts would not have been encoded.”
Just as the Library of Congress’s cataloging system assigns a string of numbers and letters to each book, the Unicode Standard links each character from every included writing system to a specific code point. Unlike a library, however, where the number of books is limited by the availability of shelf space, Unicode has enough slots left to cover the 136,690 characters already included, every unencoded script ever written, and room to spare for many more to come. The encoding process is held back by rigorous proposal reviews and the politics of reaching a worldwide consensus on how to represent each script, but less so by technical difficulties. At this point, the Unicode Standard has incorporated both Japanese Kanji, in which characters can represent whole words rather than sounds, and Egyptian hieroglyphics, in which characters are arranged in clusters. The ironing-out of these writing systems has paved the way for Mayan hieroglyphs, which pose both of these challenges and many others.

Glyph renderings courtesy Carlos Pallán Gayol; graphic design by Andrea Heiss

Glyph renderings courtesy Carlos Pallán Gayol; graphic design by Andrea Heiss
Carlos Pallán Gayol, an archaeologist and epigrapher at the University of Bonn, is working with Anderson to get this mind-bending writing system into the Unicode Standard. Mayan hieroglyphs are logosyllabic, meaning that they include signs that indicate words, signs that indicate syllables, and signs that indicate both words and syllables. A word like “mountain”(witz) can be written by a single sign representing the word, linked signs indicating its syllables, or a combination of signs indicating both the word and its syllables. To create meaning, up to seven signs are arranged in a cluster, or logogram, in which they can attach to each other on all sides like barnacles, and can even eclipse each other. Rather than being read vertically or horizontally, these clusters are arranged in columns of two, which are then read in a downward zigzag, beginning with the top left cluster and ending with the bottom right. Add to this mix the additional variable that the signs evolved over a period of 2,000 years, and one can scratch the surface of the confusion with which Mayan hieroglyphs have taunted linguists for centuries.
The long line of code-breakers to take on Mayan hieroglyphs started with Spanish colonists in the sixteenth century. A bishop named Diego de Landa convinced a Mayan scribe, Gaspar Antonio Chi, to match, letter for letter, the signs of the Mayan script and the Spanish alphabet. When the scribe heard the Spanish pronunciation of the letter ‘b,’ says Pallán, he wrote the sign for bih, which means “road.” The scribe’s frustration with de Landa is evident in the last exercise that he completed for the bishop. Asked to pen any sentence in Mayan hieroglyphs, Chi wrote: “I don’t want to.”
Early European efforts to create a global standard for writing Mayan languages have enabled the preservation of great works of literature like the Popol Vuh and Chilam Balam, but the initial attempts were fraught with miscommunications and rivalries. Garry Sparks, an assistant professor at George Mason University who received funding from NEH for his research on texts written by some of the first Spanish priests to reach the Mayan highlands, discovered competing systems for writing Mayan languages in the sixteenth-century Kislak Manuscript 1015. Along with his colleague Frauke Sachse of the University of Bonn, he has identified multiple dialects and languages in the same handwritten book. Each of these languages required the Spaniards to adapt their Latin alphabet.
Although the Franciscan friar Francisco de la Parra had already developed a standard for writing the new sounds, it seems that the Dominicans wanted to “have their own stamp on it,” says Sparks. They adapted letters from the Arabic alphabet and created new shorthands, much in the way that tech companies in the days before Unicode each used a different encoding standard. “We’re not always clear why they’re deviating,” says Sparks. “Is it for political reasons, they want to have their ‘own’ alphabet, or, as they’re moving into other languages, do they feel they need to modify the alphabet in order to customize it to these new languages?”
Decoders of Mayan hieroglyphs today face a different set of problems, many of which Unicode is poised to solve. The end of the Cold War, when Western scholars first became aware of discoveries made by the Soviet epigrapher Yuri Knorosov, ushered in an era of what specialists call “modern decipherment.” Facing an illustrated, centuries-long “Fill-in-the-Blank” puzzle, Knorosov figured out the connection between an image of a dog and a nearby cluster of signs that represented the sounds for “dog” (tzul). This breakthrough enabled him to decode a longer swath of text, and it was the catalyst for code-crackers around the world to shift into high gear.
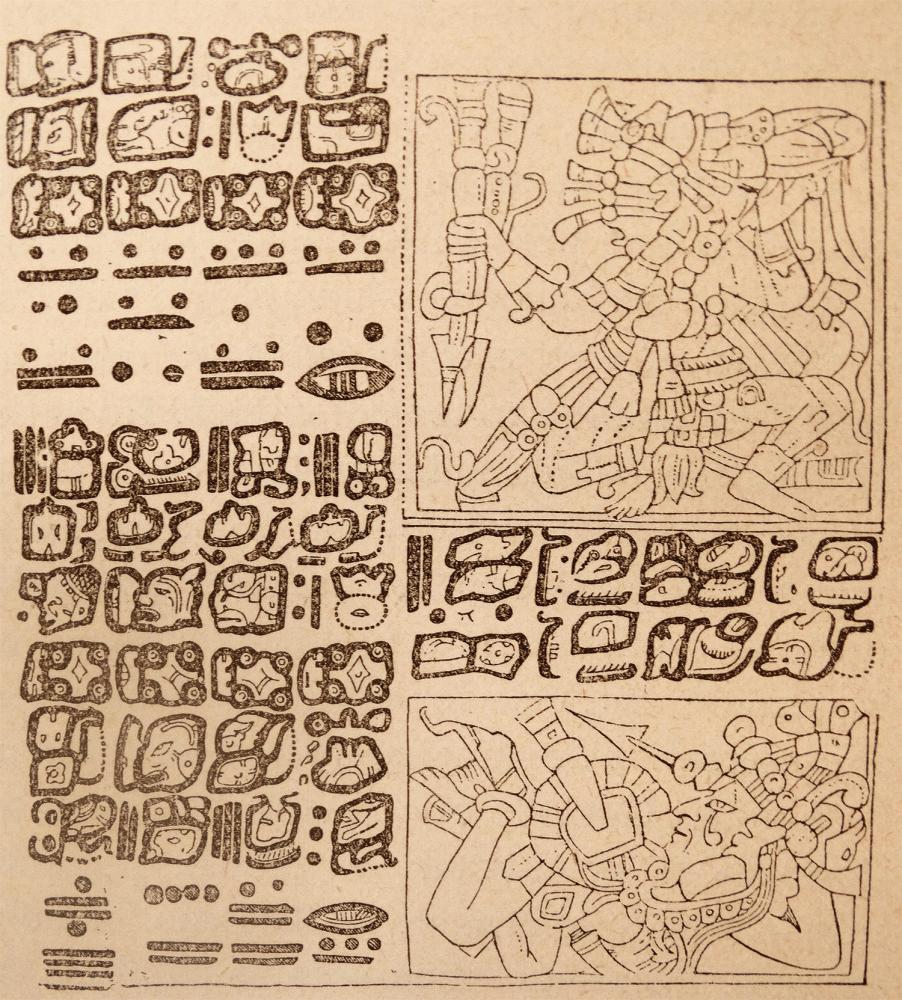
During the Cold War, Soviet scholar Yuri Knorosov advanced Mayan decipherment when he discerned that two signs consistently appeared above images of dogs on various pages of the Dresden Codex.
Wikimedia Commons
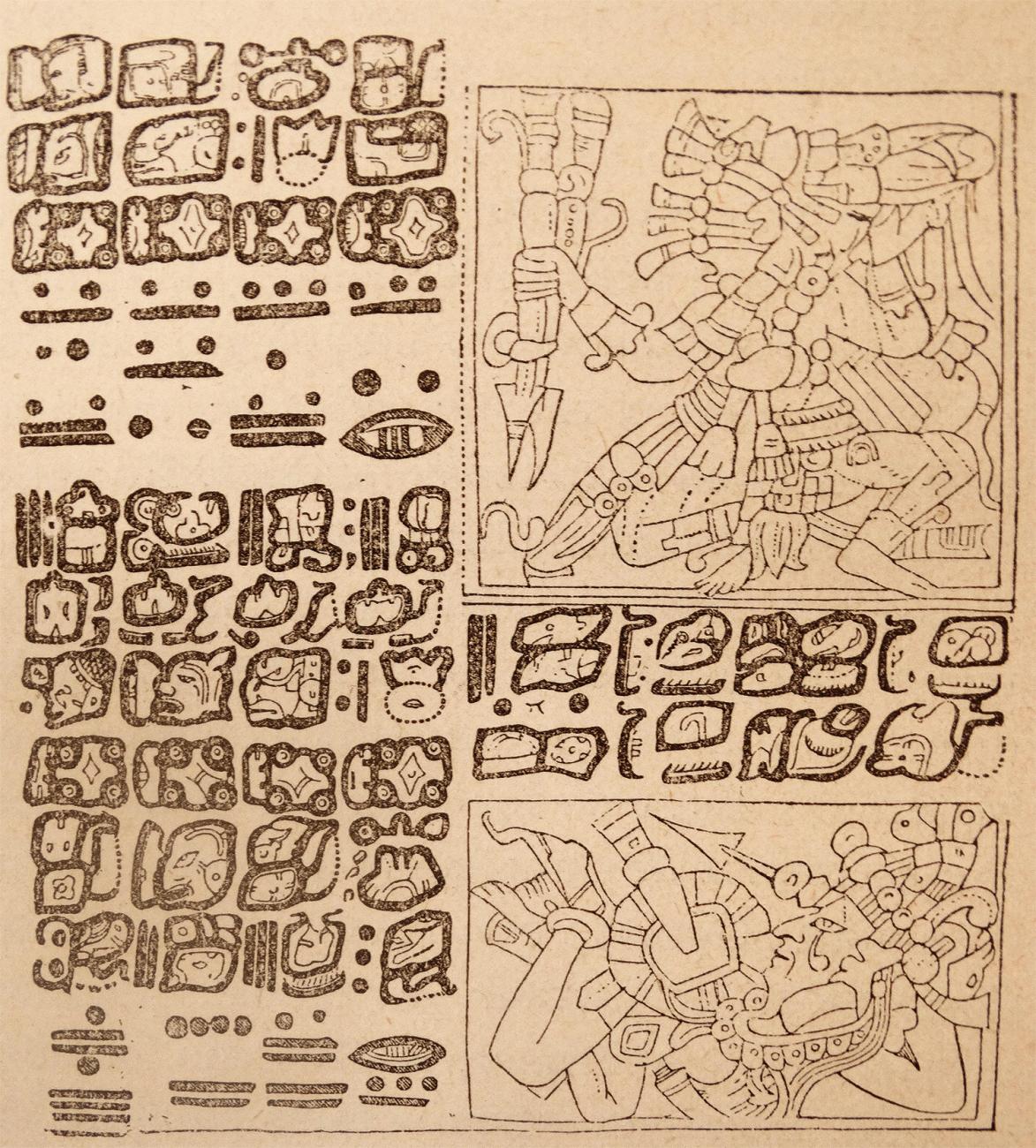
During the Cold War, Soviet scholar Yuri Knorosov advanced Mayan decipherment when he discerned that two signs consistently appeared above images of dogs on various pages of the Dresden Codex.
Wikimedia Commons
These days, says Pallán, epigraphers are unriddling new signs every month or so. Depending on how you count them, scholars have decoded approximately 85 percent of the surviving Mayan hieroglyphs. Progress has been made because of both human ingenuity and technology, since artificial intelligence, machine vision, and other methods from the digital humanities have been used to isolate signs and make connections between them.
“All of the easy decipherments are already taken,” says Pallán, “the easy ones are gone.” Now that the last and hardest signs to be unraveled rear their ugly heads, epigraphers face the problem that, over the last several decades, code-crackers around the world have used different methods to keep track of their discoveries. Without a shared standard, epigraphers cannot learn from each other’s findings, so that someone working in Paris may spend years on a cryptic sign that a Russian has already figured out.
“What you see here is literally the tower of Babel—it’s pure chaos,” says Pallán. That is why he is months away from completing a database that will catalog every surviving Mayan hieroglyph. He has started with the Dresden Codex, one of the three surviving texts that scholars generally agree contain authentic examples. Crucially, this database makes sense of the multiple coding systems that scholars all over the world have used in isolation to catalog their findings. The new lingua franca? Unicode.
Gods and demons are shown is this section of the Dresden Codex
World History Archive / Alamy Stock Photo
Gods and demons are shown is this section of the Dresden Codex
World History Archive / Alamy Stock Photo
Assigning a Unicode code point to each Mayan hieroglyph will make it possible for scholars in China, Germany, and Mexico to add to the database and collaborate on new discoveries in real time. They will be able to read and translate Mayan hieroglyph texts, meaning that those who analyze Mayan literature preserved with the Spanish alphabet can trace the origins of the literary tradition and make connections between past and present Mayan culture. As Pallán says, encoding the writing system will “build a bridge so that people won’t be talking about two separate traditions any longer. . . . It’s going to be one and the same, spanning 2,500 years.”
In time, Pallán hopes that Mayan speakers will use the hieroglyphs to write the sounds of their language more accurately than has been possible since the colonists arrived. “We want it to be as universal as possible, as open-access as possible. In essence, to democratize access,” he says. “That’s one of the main reasons that attracted scholars like me to collaborate with Unicode.”
