NEH Data Challenge Winner: Digital APUSH

AP U.S. History students at Sunapee Middle High School Library
Image courtesy of Ray Palin @raypalin on Twitter
"Student winners of the #ChronAm data challenge getting their cash awards this morning. And doughnuts! Thankyou @NEHgov
4 Oct 2016 http://bit.ly/2oieOuX"
AP U.S. History students at Sunapee Middle High School Library
Image courtesy of Ray Palin @raypalin on Twitter
"Student winners of the #ChronAm data challenge getting their cash awards this morning. And doughnuts! Thankyou @NEHgov
4 Oct 2016 http://bit.ly/2oieOuX"
This series features guest posts from the winners of the Chronicling America Historic American Newspapers Data Challenge. This article features Digital APUSH: Revealing History with Chronicling America, a site built by Librarian and History Teacher Ray Palin and the AP U.S. History Students at Sunapee Middle High School in New Hampshire.
Digital APUSH: Revealing History with Chronicling America, which won the K-12 prize in the 2016 NEH Data Challenge, was the work of fifteen history students at Sunapee Middle High School in New Hampshire, who used data analysis to uncover trends in newspaper coverage. The students, who completed the project in the final weeks of school following their Advanced Placement U.S. History Exam in early May, practiced new methods of research and publication made possible by new digital tools and increasingly available digitized content, like the historic newspapers found within the Chronicling America repository. This 2016 work continued an emphasis on digital history that began the previous year with a different group of students. In 2015, in a separate and unrelated project, students used text-analysis utilities and Google Maps to investigate and document town-by-town sympathies within the state of New Hampshire regarding ratification of the federal Constitution. This earlier project had demonstrated that, with some direction, high school history students can make small but original contributions to the scholarly record. Revealing History with Chronicling America was an effort to do that again. When I asked my students to take on the NEH challenge and create a web-based project using data pulled from Chronicling America, they were eager to start.
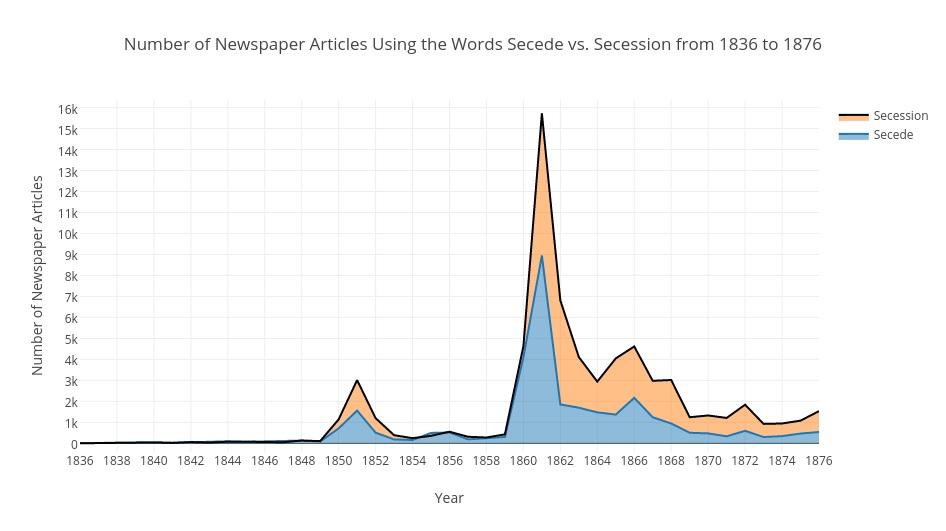
Graph by students Connor Fleury, Miles O'Mara, and Andrew Sarnevitz
http://bit.ly/2ohQeKM
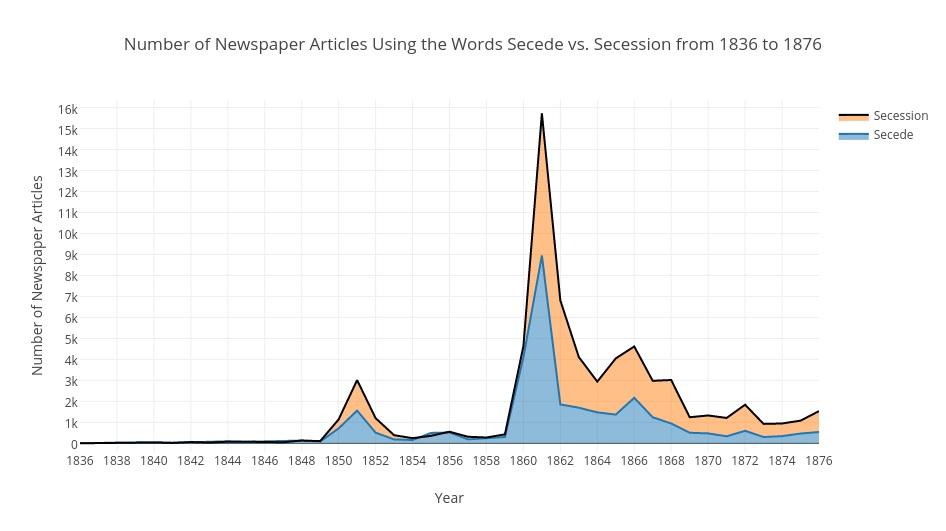
Graph by students Connor Fleury, Miles O'Mara, and Andrew Sarnevitz
http://bit.ly/2ohQeKM
My students’ work was inspired by a crowdsourced history project undertaken by the United States Holocaust Memorial Museum, one where "citizen historians" look within sources like newspapers.com for nationwide coverage of the Holocaust. Like these volunteer researchers, my students searched for specific news items, looking for both patterns of coverage and lack of coverage. One goal of this work, like that of the Holocaust Museum's research, was to uncover geographic differences among newspapers and to speculate as to why. While the ongoing Holocaust project requires researchers to read and evaluate stories (close reading), my students’ work relied on word-frequency analysis (distant reading) made possible by using search techniques like proximity searching, which reveals the extent to which a phrase or phrase variation is found within a vast collection of records.
Before searching and working with Chronicling America content, students were introduced to research methods useful for finding meaning within large sets of data. After reading introductory articles (e.g., “Visualization as an Introduction to Text Mining?”) and watching several YouTube videos, including “Big Data + Old History” which nicely explains the concept of distant reading, students were ready to consider another research concept. They were asked to think about the idea of finding something by finding nothing. More specifically, students were asked to think about the National Holocaust Museum’s research project and about why some newspapers failed to cover events like Kristallnacht. It was concluded that by not finding something in newspapers, my students could potentially find a lot. The omission of information might signal disinterest or perhaps even a whitewashing.
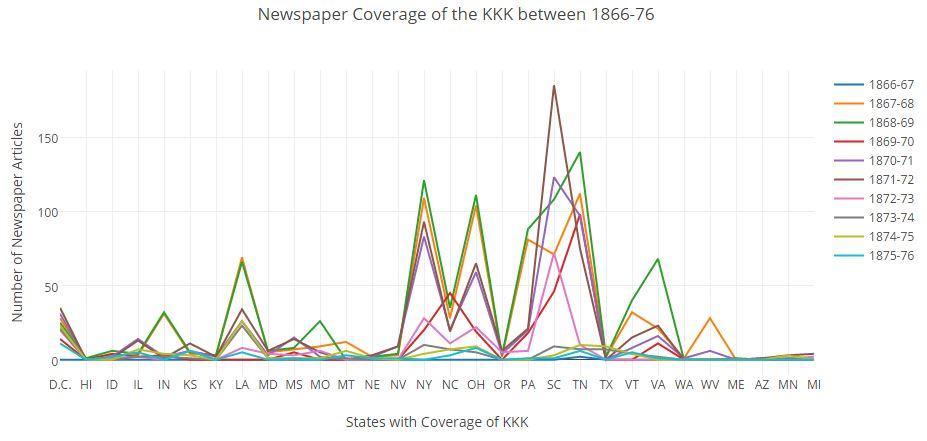
Graph by students Lynnsey Trabka, Maryann Cousins, and Meghan Frederick https://plot.ly/~trab544/1/

Graph by students Lynnsey Trabka, Maryann Cousins, and Meghan Frederick https://plot.ly/~trab544/1/
With these ideas—distant reading and information omission—as the backdrop, the class was guided in a model investigation within Chronicling America. Working in small groups, students examined nationwide coverage of the Plessy v. Ferguson court case. As expected, different groups produced different findings, creating a useful teaching opportunity for refining search techniques and exploring alternative approaches to data collection. Following short lessons on search techniques, accessing and downloading web content, and organizing data into spreadsheets, students searched again and worked with their new data to produce visualizations about the Plessy findings. Using this initial work as a blueprint for additional research, they went on to pursue their own investigations, identifying trends in newspaper coverage for several other U.S. history topics. Revealing History with Chronicling America showcases the best of these investigations.
Student Virgile Bissonnette-Blais presents at NEH Headquarters
Image courtesy of Melissa Jerome @mmespino20 on Twitter
#NDNP #ChronAm project by Sunapee High students chronicling use of #KKK in historic #newspapers
14 Sep 2016
http://bit.ly/2oPpxA3
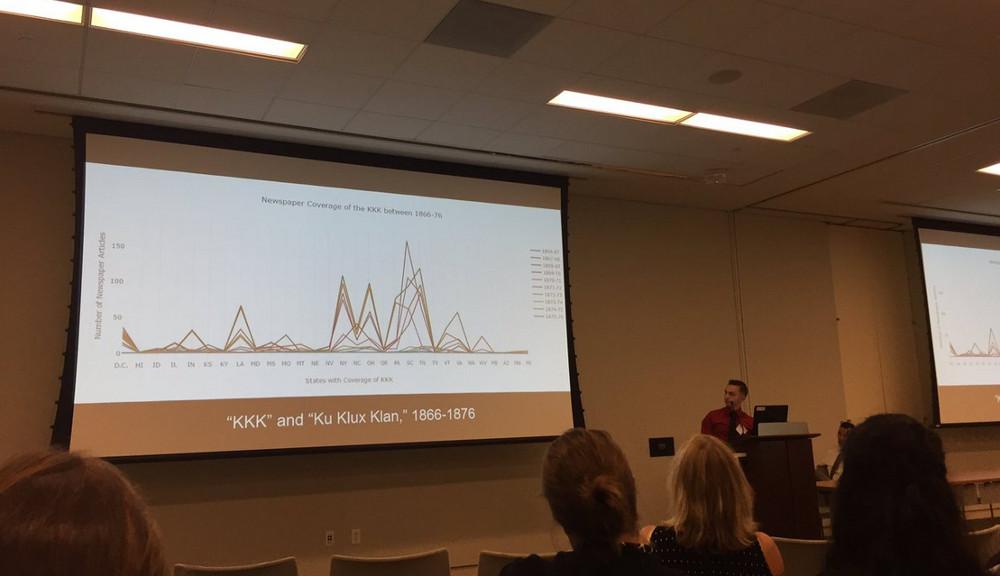
Student Virgile Bissonnette-Blais presents at NEH Headquarters
Image courtesy of Melissa Jerome @mmespino20 on Twitter
#NDNP #ChronAm project by Sunapee High students chronicling use of #KKK in historic #newspapers
14 Sep 2016
http://bit.ly/2oPpxA3
The NEH data challenge created a new type of research assignment for my students—one that resulted in a product, not a paper, and one made possible by new types of historical queries. By encouraging the public to use data to explore history, NEH encouraged me and my students to hack the traditional high school research paper process and to try new approaches to history class. My students experimented with a form of text mining as they extracted information from text records in order to answer questions about the past. Then, in order to complement their writing and display insights from their findings, they created a series of data visualizations by using a wide range of web tools that they discovered and learned to use for the first time. In the end, I’d like to think that my students did history and didn’t simply read and write about it. In fact, I’d like to say that by expanding their skill sets, by thinking differently about the past, and by practicing a new form of scholarship, they acted like 21st-century apprentice historians intent on modernizing an age-old discipline.

Student Virgile Bissonnette-Blais at NEH Headquarters
Image courtesy of Ray Palin @raypalin on Twitter
With @vblais17 presentinghttp://apush.omeka.net/2016 to members of @NEHgov + @librarycongress #ChronAm
14 Sep 2016
http://bit.ly/2oPpdS0

Student Virgile Bissonnette-Blais at NEH Headquarters
Image courtesy of Ray Palin @raypalin on Twitter
With @vblais17 presentinghttp://apush.omeka.net/2016 to members of @NEHgov + @librarycongress #ChronAm
14 Sep 2016
http://bit.ly/2oPpdS0
The Chronicling America Historic American Newspapers Data Challenge invited members of the public to create web-based projects using the historic newspaper data in Chronicling America. Entrants were to explore important humanities themes using technology including visualizations, maps, tools, and data mashups. Chronicling America is an open access, searchable database of historic U.S. newspapers produced by a long-term partnership between NEH and the Library of Congress. It includes millions of pages of digitized newspapers and descriptive information contributed by states and territories across the country. The Library of Congress provides the data through a well-documented API to enable exploration of the collection in a variety of ways beyond the site’s popular web interface. Visitors view around 40 million web pages in Chronicling America each year, and some also use the open API to explore the historic newspapers as big data. This openness allows users both to view individual pages and download big data sets used to show trends over time and space.